In this post, I will detail the steps I followed in building a JSON parser well enough for anyone with some programming knowledge and willingness to know what a parser and lexer are to follow along.
This JSON parser is built as part of the coding challenges by John Cricket and this particular attempt at the challenge is probably not the best out there. I expect there are better ways to do several things, but the primary aim for me was to have fun building 😄
STEP 0 - Grammar as the grand start
Grammar, in the theory of computation, refers to a set of rules that define acceptable strings in a language. Quite similar to grammar in the English language if you ask me. Think of how you know “I can sing” is a correct sentence but “I sing can” isn’t.
The role of the parser—in a compilation process—is to validate syntactic structure. It accepts a sequence of tokens—to be discussed next—and checks that the sequence is valid according to the language’s grammar.
Right before the parser gets into action, there is the lexer. The lexer, also usually a part of the compiler, is responsible for reading the text you write and creating meaningful tokens of it. A token is the simplest meaningful unit in a language. Take a look at the examples here to better understand what tokens are.
Back to the grammar; for the parser to know what sequence of tokens is valid, we clearly define the acceptable sequence i.e. the grammar. As a similar reference, in the English language modal verbs, such as “can”, always come before the main verb, such as “sing” hence why the sentence “I can sing” is valid and the other isn’t.
I came up with the following grammar for JSON. The grammar references json.org for notation and structure.
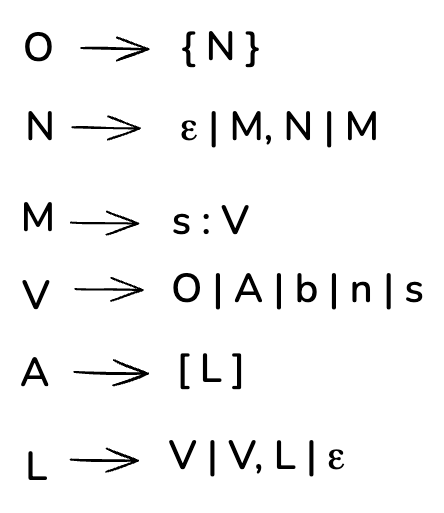
The notation above may be strange if you’re unfamiliar with the topic; It is a common way of representing grammar using production rules—each line with an arrow. This particular set of production rules is interpreted as the following from top to bottom:
- An object (O), identified with an open brace, a list of members(N), followed by the closed brace. A member refers to a key-value pair
- A list of members (N) represented either by an empty string, a member(M), or a member(M) followed by a comma, followed by a list of members (N)
- A member(M) is identified as a string followed by a colon(:) followed by a value (V)
- A value(V) identified as either an object (O), an array (A), a boolean (b), null (n), or a string(s)
- An array(A) is identified as a left bracket followed by a list of elements(L) followed by a right bracket
- A list of elements identified as a single value, a value followed by a comma, followed by another list of elements of an empty string
STEP 1.1 Lexer, but just open and close
For this step, I built a lexer that recognizes the { and } characters as tokens. To begin with the lexer, a Lexer class:
class Lexer:
def __init__(self, input: str):
self.position = 0
self.input = input
self.line_number = 1
def readCharacter(self) -> None | str:
if self.position >= len(self.input):
return None
character = self.input[self.position]
self.position += 1
return characterThe class has a readCharacter method, which returns the character to the current position on every call and increments the position. The idea is to use the position as a pointer and iterate through every character in the text input. I hope to use the line_numberattribute for error reporting 🤞
To recognize the different types of tokens, I use a Token class with a type attribute and a literal for actually storing the string/character:
from enum import Enum
class TokenTypes(Enum):
LEFT_BRACE = "left_brace" # {
RIGTH_BRACE = "right_brace" # }
EOF = "eof" # mark end of file
class Token:
def __init__(self, literal: str, type: TokenTypes):
self.literal = literal
self.type = type
def __repr__(self) -> str:
return f"Token[literal: '{self.literal}', type: {self.type.name}]"The only types known for now are the left brace, the right brace, and an EOF type I use to recognize when we have read all of the text.
The parser mostly needs the lexer to produce the next token in the sequence so I make a method in the Lexer class for this; every time it’s called, the lexer returns the next token in the sequence
class Lexer:
...
def nextToken(self):
character = self.readCharacter()
token = None
if character == "{"
token = Token(character, TokenTypes.LEFT_BRACE)
elif character == "}":
token = Token(character, TokenTypes.RIGHT_BRACE)
elif character == None:
token = Token("", TokenTypes.EOF)
else:
raise Exception(f'character at position {self.position - 1} not recognised')
return tokenNotes on the Exceptions using
self.positionThe idea of raising errors with messages having the position was to replicate error messages that point you to the particular position on a line where the error occurred. This worked well with single line text but to get it accurate for multiple lines would require work I am yet to get to as of now
That’s all for the basic lexer 🤩 . Way easier than the earlier explanation of what a lexer is right?
I wrote some unit tests to test things out but I’ll leave that out of this post. The final set of tests can be found in the GitHub repo.
STEP 1.2 Parser, but just open and close
Next comes building the parser capable of parsing an empty object {}. As with the Lexer, I use a Parser class for everything related:
class Parser:
def __init__(self, input: str) -> None:
self.lexer = Lexer(input)
self.currentToken = None # Current token to parse
self.peekToken = None # Next token that will be parsed. Knowing this will be useful for selecting valid rules.
def nextToken(self):
self.currentToken = self.peekToken
self.peekToken = self.lexer.nextToken()The class uses an instance of the lexer class for getting tokens — from the input text. The nextToken is used for setting the currentToken attribute to the next token to be evaluated. A peekToken attribute also exists in the class for the token right after the current token. This allows the parser to take a “peek” ahead.
To parse the JSON, I explored the concept of a recursive descent parser. More about that here. Parsers are split into top-down parsers and bottom-up parsers. Recursive descent parsing is an approach to top-down parsing I found fairly easy to implement. The idea — of recursive descent parsing — as I came to understand it is to have a procedure/function representing each non-terminal in my grammar — the big letters in the above grammar. Each of these functions will attempt to parse the following tokens according to the right-hand side of the production rule. If another(or the same) non-terminal is part of the production rule, the function for this non-terminal is called, hence the recursive part of the name.
Getting into actual coding; First I need a function that actually starts the parsing
class Parser:
...
def parseProgram(self) -> ProgramNode:
# Call next token twice to allow currentToken and peekToken to be properly initialised
self.nextToken()
self.nextToken()
program_node = ProgramNode()
if self.currentToken.type == TokenTypes.LEFT_BRACE:
parent_object: ObjectNode = self.parseObject()
program_node.parent_object = parent_object
else:
raise SyntaxError(f'Invalid token {self.currentToken.literal}')
return program_nodeThe parseProgram method is to be called to begin the process. It calls self.nextToken twice to initialize the currentToken and peekToken to actual tokens. JSON — an object notation — is a bunch of members wrapped in an object so the first token to expect in a valid JSON should be the start of an object, { — the left brace.
If the currentToken is a left brace, then it’s fair to assume we’re dealing with an object and try to parse the object by calling the parseObject method shown below:
class Parser:
...
def parseObject(self):
object_node = ObjectNode()
self.nextToken()
if self.currentToken.type != TokenTypes.RIGTH_BRACE:
pass
else:
raise SyntaxError(f'Invalid token {self.currentToken.literal}')
return object_nodeIn this method, I check that the next token is a right brace. And that’s all, the parser now recognizes the JSON {}
Nodes - Note on the node objects seen so far
The ObjectNode and ProgramNode classes seen so far refer to nodes of an Abstract Syntax Tree(AST). The parser as part of the compilation process is responsible for generating an abstract syntax tree to be utilized by the following stages of the process. In the code so far, I have created these nodes but I have chosen not to discuss the nodes or the AST to leave the post less complex.
STEP 2.1 More strings, more power to the Lexer
To allow the Lexer to recognize strings both for member names and member values, I add a string token type to the set of known types
class TokenTypes(Enum):
...
STRING = "string" # a stringIn the lexer’s nextToken method, we recognize strings as a sequence of characters that start and end with a quotation mark.
class Lexer:
...
def nextToken(self):
character = self.readCharacter()
token = None
if character == "{":
token = Token(character, TokenTypes.LEFT_BRACE)
...
elif character == '"':
name = self.readString()
token = Token(name, TokenTypes.STRING)
else:
raise Exception(f'character at position {self.position - 1} not recognised')
return tokenWhen the currently read character is “ the set of characters that follow should make up a string, and I use the readString method to read these characters into one Python string.
class Lexer:
def readString(self):
string = ""
while char := self.readCharacter():
if char == '"':
break
else:
string = string + char
return stringThe nextToken method uses the string literal returned in creating a token and returns that token.
While we’re on strings; the lexer should also recognize commas and colons. The token types are added as that for strings was:
class TokenTypes(Enum):
...
STRING = "string" # a string
COLON = ":" # colon token type
COMMA = "comma" # comma `,`The nextToken can easily recognize these characters so the tokens are easily created
class Lexer:
...
def nextToken(self):
...
elif character == ':':
token = Token(character, TokenTypes.COLON)
elif character == ",":
token = Token(character, TokenTypes.COMMA)STEP 2.2 What about spaces
So far the lexer has iterated through the text assuming every character is a recognized one or it throws an error. But in writing JSON {"hey":"there"} is just as valid as { "hey": "there"}. The space between tokens should be ignored. The lexer currently will throw an error whenever it meets a space character. I fix this by adding every space character as a recognized one but not returning as a token, instead, keep reading the next characters until we get to read a valid token
class Lexer:
...
def nextToken(self):
...
elif character.isspace():
# If character is space, skip it
self.skipSpaces()
return self.nextToken()The skip spaces method keeps reading characters until we get to a non-space character, then we call nextToken again so we get the next viable token
class Lexer:
...
def skipSpaces(self):
while char := self.readCharacter():
if char.isspace():
if char == '\n' or char == '\r':
self.line_number += 1
continue
else:
self.position -= 1
breakSkipping the spaces is a good enough solution for handling spaces for JSON, In a programming language where space is actually a valid/required part of the syntax the space may actually be kept as a token — I think?
STEP 2.3 Parser’s first steps
To take some baby steps, the parser should be able to parse {"name": "samuel"} — Object, with a single member whose key and value are strings. The lexer already recognizes string tokens and the semi-colon token so I only need the Object to call the procedure to parse a member. Remember I said a procedure/method will exist for each non-terminal.
To add this, I updated the parseObject procedure as such:
class Parser:
...
def parseObject(self):
object_node = ObjectNode()
self.nextToken()
while self.currentToken.type != TokenTypes.RIGTH_BRACE:
if self.currentToken.type == TokenTypes.STRING:
member = self.parseMember()
object_node.members.append(member)
self.nextToken()
else:
raise SyntaxError(f'Invalid token {self.currentToken.literal}')
return object_nodeThe change adds a check to see if the current token is a string type. If it is, it’s okay to assume we’re now dealing with a member (a key-value pair), so I call the function to parse a member. The function to parse a member checks that the next token after the string (the key) is a colon, otherwise it throws an error and skips the colon to the next token, then checks that this current token is also a string(the value).
class Parser:
...
def parseMember(self) -> MemberNode:
member_node = MemberNode()
if self.peekToken.type != TokenTypes.COLON:
raise SyntaxError('Colon required in defining a member')
member_node.key = self.currentToken
# Skip the colon and go to the next token
self.nextToken()
self.nextToken()
if self.currentToken.type != TokenTypes.STRING:
raise SyntaxError("A member requires a string value")
return member_nodeWith these changes, the parse can now parse the JSON {"name": "samuel"}.
STEP 2.4 Enough steps to walk
For the next step, I update the parser to recognize JSON with multiple key-value pairs like {"name": "samuel", "random": "yes"}. To do this the parser needs to know to expect a comma after every member except the last one.
class Parser:
...
def parseObject(self):
...
while self.currentToken.type != TokenTypes.RIGHT_BRACE:
if self.currentToken.type == TokenTypes.STRING:
member = self.parseMember()
object_node.members.append(member)
self.nextToken()
if self.currentToken.type == TokenTypes.COMMA: # If the current token is a comma
if self.peekToken.type == TokenTypes.STRING: # If the next token is a string, then there are more members to follow
self.nextToken() # Skip the comma
# Otherwise do nothing
else: # If the current token is not a comma, then that better be the end
if self.currentToken.type != TokenTypes.RIGHT_BRACE:
raise SyntaxError(f'Comma expected before next member')
else:
raise SyntaxError(f'Invalid token {self.currentToken.literal}')
return object_nodeWith this change, the parser after parsing a member checks if the next token is a comma, if it is, then it skips the comma for the loop to parse the next member in the next iteration. If it isn’t a comma, then it’s expected to be a right brace.
That’s it! the parser can now parse JSON with all its values as strings.
STEP 3.1 A bigger lexer
To improve the lexer’s capability, I updated it to recognize numerics, booleans, null, left bracket, and right bracket as tokens.
As usual, I added the new token types;
class TokenTypes(Enum):
...
LEFT_BRACKET = "left_bracket" # [
RIGHT_BRACKET = "right_bracket" # ]
NUMERIC = "numeric"
BOOLEAN_TRUE = "true" # true
BOOLEAN_FALSE = "false"
NULL = "null"With the token types added, the lexer can be updated to identify the relevant tokens. Identifying the left and right brackets is easier to do:
def nextToken(self):
character = self.readCharacter()
token = None
if character == "{":
token = Token(character, TokenTypes.LEFT_BRACE)
self.tokens.append(token)
...
elif character == "]":
token = Token(character, TokenTypes.RIGHT_BRACKET)
self.tokens.append(token)
elif character == "[":
token = Token(character, TokenTypes.LEFT_BRACKET)
self.tokens.append(token)
...
else:
raise Exception(f'character at position {self.position - 1} not recognised')
return tokenIdentifying booleans, null, and numeric required extra functions for actually reading the next sequence of characters. A readNumeric method in the lexer for reading numerics :[
class Lexer:
def readNumeric(self):
numeric = self.input[self.position - 1]
while char := self.readCharacter():
if not char.isnumeric():
break
else:
numeric = numeric + char
self.position -= 1
return numericThe method reads a new character until it gets to one that isn’t numeric. Right before it returns I adjust the position attribute one step backward so the next call to nextToken reads the right character.
Also, a readKeyword method in which I read booleans(true or false) and the null type.
keywords = {"true": TokenTypes.BOOLEAN_TRUE, "false": TokenTypes.BOOLEAN_FALSE, "null": TokenTypes.NULL}
class Lexer:
...
'''
This checks if a set of characters is either a boolean value or null
'''
def readKeyword(self):
start_position = self.position - 1
keyword = self.input[start_position]
while char := self.readCharacter():
if not char.isalpha():
break
else:
keyword = keyword + char
if keyword in keywords.keys():
token_type = keywords[keyword]
self.position -= 1
return keyword, token_type
else:
raise Exception(f'character at position {start_position} not recognised')This method is similar to readString but with the addition of the if condition which checks if the string we have so far is in the known list of keywords. There’s also the important difference with when the functions are called. The readString is called when we get to a quote character — identifies the beginning of a string — while the readKeyword is called when we get to an alphabet character.
with that sorted, the lexer can now read and identify those token types:
class Lexer:
...
def nextToken(self):
character = self.readCharacter()
token = None
if character == "{":
token = Token(character, TokenTypes.LEFT_BRACE)
...
elif character.isnumeric():
numeric = self.readNumeric()
token = Token(numeric, TokenTypes.NUMERIC)
elif character.isalpha():
keyword, token_type = self.readKeyword()
token = Token(keyword, token_type)
...
return tokenSTEP 3.2 A bigger parser
With the lexer able to identify all possible tokens, the parser can be updated to parse all the possible types for a value.
I modified the procedure for parsing a member; instead of just checking that the value is a string the parser should attempt to parse the value using the procedure parseValue
class Parser:
...
def parseMember(self) -> MemberNode:
...
member_node.value = self.parseValue()
return member_node
def parseValue(self) -> Token:
valueNode = ValueNode()
accepted_value_token_types = [TokenTypes.STRING, TokenTypes.NUMERIC, TokenTypes.BOOLEAN_FALSE, TokenTypes.BOOLEAN_TRUE, TokenTypes.NULL]
if self.currentToken.type in accepted_value_token_types:
valueNode.value = self.currentToken
elif self.currentToken.type == TokenTypes.LEFT_BRACKET:
arrayNode = self.parseArray()
valueNode.value = arrayNode
elif self.currentToken.type == TokenTypes.LEFT_BRACE:
objectNode = self.parseObject()
valueNode.value = objectNode
else:
raise SyntaxError(f'Invalid token for value: {self.currentToken.literal}')
return valueNodeThe procedure checks that the current token type is in one of the accepted value types. You’ll also notice another procedure for parsing arrays. If the current token type is a left bracket then we should be at the beginning of an array so the function parseArray is called
class Parser:
...
def parseArray(self):
arrayNode = ArrayNode()
self.nextToken()
accepted_value_token_types = [TokenTypes.STRING, TokenTypes.NUMERIC, TokenTypes.BOOLEAN_FALSE, TokenTypes.BOOLEAN_TRUE, TokenTypes.NULL]
while self.currentToken.type != TokenTypes.RIGHT_BRACKET:
if self.currentToken.type in accepted_value_token_types:
arrayNode.elements.append(self.currentToken)
self.nextToken()
if self.currentToken.type == TokenTypes.COMMA:
if self.peekToken.type in accepted_value_token_types:
self.nextToken()
else:
raise Exception(f'Unrecognised array element {self.peekToken.literal}')
else:
if self.currentToken.type == TokenTypes.RIGHT_BRACKET:
continue
else:
raise Exception(f'Unrecognised array element {self.currentToken.literal}')
else:
raise Exception(f'Unrecognised array element {self.currentToken.literal}')
return arrayNodeParsing of an array generally involves checking that until we meet a right bracket that closes the array, we keep getting a sequence of acceptable tokens in an array always split by a comma.
In the parseValue method, you’ll also notice a parseObject call; this calls the same function we call when we begin to parse the program because remember, the first thing in JSON is an object.
That’s it. The parser is now capable of parsing JSON as complex as this:
{
"key": "value",
"key-n": 101,
"key-o": {
"inner key": "inner value"
},
"key-l": ["list value"]
}There are several tests for the parser in the codebase for automated tests but running this parser would look something like this:
python json-parser --file test.jsonThe parser in this case would attempt to parse test.json and throw an error if the JSON in the file is invalid.
I had fun building and look forward to doing more similar projects. Until then, cheers 🥂